Building RAG Systems Using Ollama, OpenWebUI, AI models, and Vector Databases.
It’s been a few months since I started working on Retrieval-Augmented Generation (RAG) systems, and it’s been one of the most rewarding learning curves in recent memory. I’ve spent that time experimenting, breaking things, and figuring out what it really takes to build a RAG pipeline that’s reliable, scalable, and production-worthy.
One of the biggest challenges in any organization is making internal knowledge accessible without sacrificing privacy or control. You want the power of large language models, but you don’t want to ship your data off to external APIs. RAG solves that problem.
By combining retrieval from your private data sources with generation from an LLM, you get a system that’s both smart and secure. You control the data, the logic, and the output.
The Basics of RAG Systems
Retrieval-Augmented Generation (RAG) systems blend the capabilities of large language models with external knowledge sources to produce accurate, context-aware responses.
- Knowledge Base: A collection of documents or data that the system can retrieve information from.
- Embedding Model: Converts text into vector representations for efficient similarity search.
- Vector Database: Stores the embeddings and allows for fast retrieval of relevant documents based on user queries.
- Language Model: Generates answers based on the retrieved documents and the user’s query
Tools and Technologies Used
-
Ollama: A local model serving platform that lets you run language models like Mistral, Llama, and others directly on your machine. Great for full control and no cloud dependency.
-
OpenWebUI: A web-based interface for interacting with models running on Ollama. Useful for testing, debugging, and iterating on RAG flows in a clean UI.
-
Vector Database: Qdrant is used to store and query embeddings. It supports fast similarity search and integrates well with most embedding workflows.
-
Embedding Models: Models like
mxbai-embed-large:latestfrom Ollama are used to convert text into embeddings. -
Chunking: Splitting documents into smaller, manageable pieces to improve retrieval accuracy.
Building the RAG System
Setting up the Environment
-
Install Ollama: Follow the official installation guide to set up the Ollama server on your machine. This will allow you to run models like llama3, mistral, and others locally.
-
Install OpenWebUI: Use OpenWebUI as a front-end to interact with your local models. We’ll use Docker to run it. You’ll find the
docker-compose.ymlsetup in the below. -
Install Qdrant: Use Docker to run Qdrant using Docker to manage your document embeddings. It handles vector storage and retrieval efficiently and integrates smoothly with your embedding pipeline.
version: '3.8'
services:
open-webui:
image: ghcr.io/open-webui/open-webui:v0.6.14
container_name: open-webui
ports:
- "3000:8080"
volumes:
- ./data:/app/backend/data
extra_hosts:
- "host.docker.internal:host-gateway"
restart: always
tty: true
environment:
QDRANT_URI: http://qdrant:6333
VECTOR_DB: qdrant
qdrant:
image: qdrant/qdrant
ports:
- "6333:6333"
volumes:
- ./qdrant:/qdrant/storage
Creating the Knowledge Base
Preparing Documents
Gather your documents in Markdown format. For example, you can create a docs directory with files like doc1.md, doc2.md, etc.
Setting up embedding models
We will be using the mxbai-embed-large:latest model from Ollama for embedding our documents. Goto settings

Creating knowledge base and uploading documents
-
Use OpenWebUI to upload your documents to the knowledge base. The UI will take care of chunking and embedding automatically no need to preprocess manually.
-
Once OpenWebUI is running, go to knowledge Base section and upload your files directly through the interface.

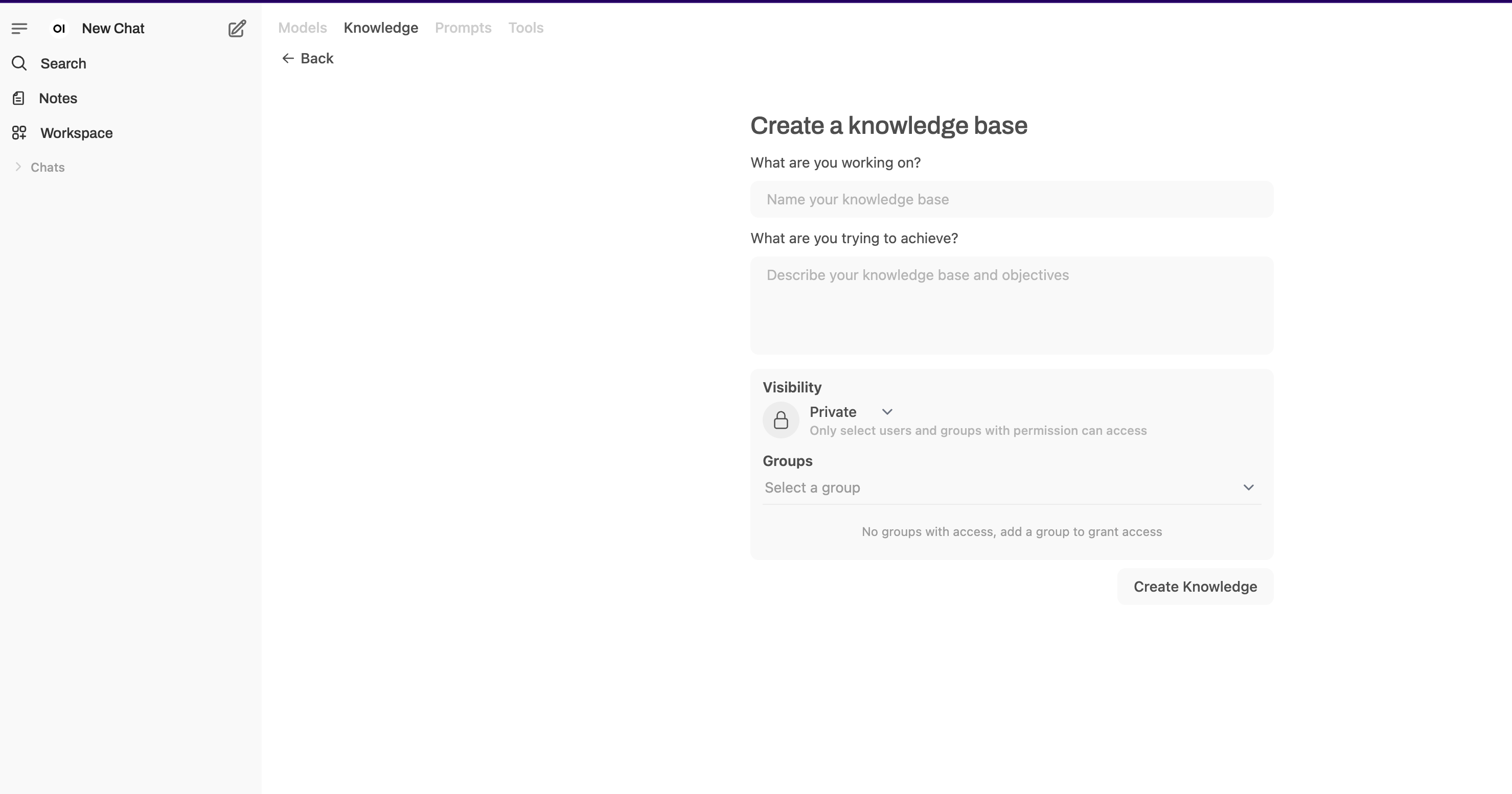
Once your Knowledge Base is created in OpenWebUI, select it from the list and upload your documents. The UI will handle chunking and embedding automatically, so you don’t have to worry about the low-level processing.

Using knowledge base in RAG system
Once your knowledge base is ready, you can start using it in your RAG workflow. OpenWebUI provides a chat interface that lets you query the knowledge base and generate answers in real time.
To get started: 1. Open a new chat in OpenWebUI. 2. Use the # symbol to select the knowledge base you created. 3. Ask a question as you normally would.
The system will retrieve relevant documents from the knowledge base and pass them to the language model, which generates a context-aware response.

Once you ask a question, the system retrieves the most relevant documents from your knowledge base and uses the language model to generate a contextual, accurate answer.
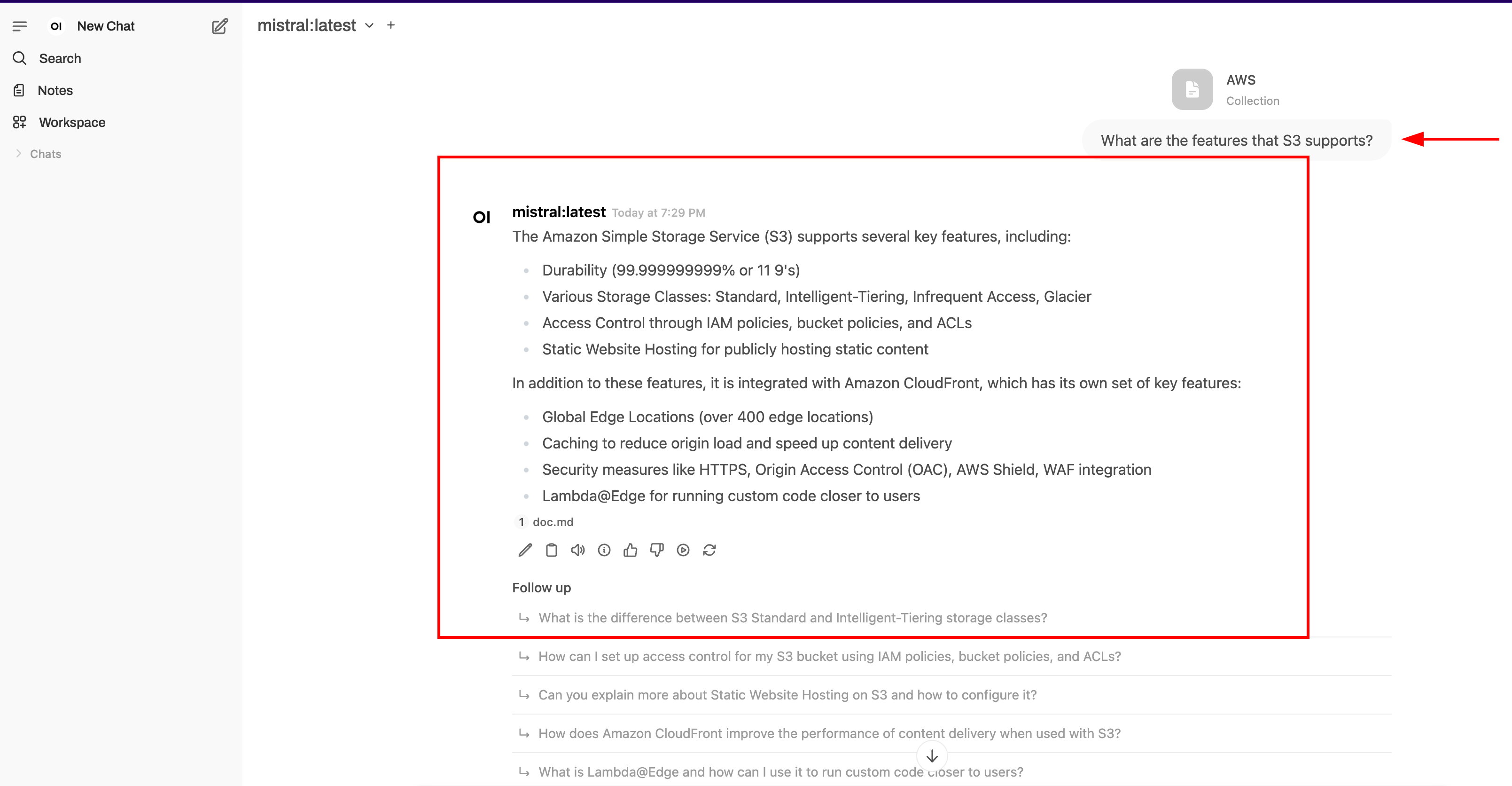
For example, try asking:
What are the features that S3 supports?
The system will search your uploaded documents for relevant content and generate an answer based entirely on that information. Here’s a sample response based on the data you provided
Conclusion
Building a RAG system with Ollama, OpenWebUI, and a vector database like Qdrant is a practical way to harness the power of AI without compromising data privacy. By following the steps in this post, you can set up a solid foundation that handles a wide range of documents and user queries with ease.
This setup covers the essentials, but there’s plenty of room to grow. In future posts, I’ll explore how to extend this system with features like custom chunking logic, different embedding models, and integrations with external AI services to make it even more flexible and production-ready.
